<input type="email"/>
пробелы + проверка на сервере === собственная валидация
//MDN
/^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+
@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}
[a-zA-Z0-9])?(?:\.[a-zA-Z0-9]
(?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*
$/
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])






a*b*c*
a*b*c*


"a" -> переход в "S1"
"b" -> переход в "S2"
"c" -> переход в "S3"
//Матрица переходов
const TRANSITIONS = [...];
//Входная строка (например "abbbcc")
const input = ...
let i = 0
let state = 0;
while (input[i]) {
state = TRANSITIONS[state][input[i++]]
}
//Матрица переходов
const TRANSITIONS = [...];
//Входная строка (например "abbbcc")
const input = ...
let i = 0
let state = 0;
while (input[i]) {
state = TRANSITIONS[state][input[i++]]
}


"a"
"b"
"c"
/^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+
@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}
[a-zA-Z0-9])?(?:\.[a-zA-Z0-9]
(?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$/
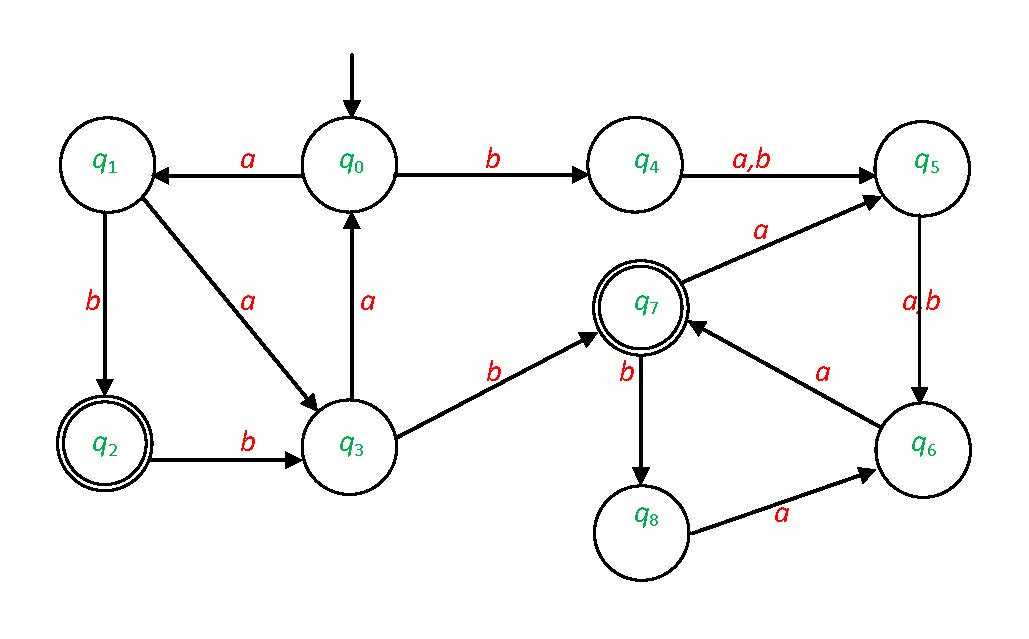
RegEx в DFA и NFA.Контекстно-свободная грамматика это четверка :

Exp -> Term + Exp
| Term
Term -> ( Exp )
| Int * Term
| Int
Int -> 1 | 2 | 3 |
4 | 5 | 6 |
7 | 8 | 9 | 0
1 + 3 * ( 8 + 5 )
Exp -> Term + Exp
| Term
Term -> ( Exp )
| Int * Term
| Int
Int -> 1 | 2 | 3 |
4 | 5 | 6 |
7 | 8 | 9 | 0
Exp -> Term + Exp
| Term
Term -> ( Exp )
| Int * Term
| Int
Int -> 1
| 2
| 3
| 4
| 5
| 6
| 7
| 8
| 9
| 0
const Exp = () => {
return Term + Exp
| Term
}
const Term = () => {
return ( Exp )
| Int * Term
| Int
}
const Int = () => {
return 1
| 2
| 3
| 4
| 5
| 6
| 7
| 8
| 9
| 0
}
const Exp = () => {
return Term() + Exp()
| Term()
}
const Term = () => {
return ( Exp() )
| Int() * Term()
| Int()
}
const Int = () => {
return 1
| 2
| 3
| 4
| 5
| 6
| 7
| 8
| 9
| 0
}
const Exp = () => {
return ( Term() && + && Exp() )
|| ( Term() )
}
const Term = () => {
return ( ( && Exp() && ) )
|| ( Int() && * && Term() )
|| ( Int() )
}
const Int = () => {
return ( 1 )
||( 2 )
||( 3 )
||( 4 )
||( 5 )
||( 6 )
||( 7 )
||( 8 )
||( 9 )
||( 0 )
}
const match = (term) => {}
const Exp = () => {
return ( Term() && match(+) && Exp() )
|| ( Term() )
}
const Term = () => {
return ( match(() && Exp() && match()) )
|| ( Int() && match(*) && Term() )
|| ( Int() )
}
const Int = () => {
return ( match(1) )
|| ( match(2) )
|| ( match(3) )
|| ( match(4) )
|| ( match(5) )
|| ( match(6) )
|| ( match(7) )
|| ( match(8) )
|| ( match(9) )
|| ( match(0) )
}
let i = 0
const match = (term) => {}
const Exp = () => {
const s = i;
return (i = s, Term() && match("+") && Exp() )
|| (i = s, Term() )
}
const Term = () => {
const s = i;
return (i = s, match("(") && Exp && match(")") )
|| (i = s, Int() && match("*") && Term() )
|| (i = s, Int() )
}
const Int = () => {
const s = i;
return (i = s, match("1") )
|| (i = s, match("2") )
|| (i = s, match("3") )
|| (i = s, match("4") )
|| (i = s, match("5") )
|| (i = s, match("6") )
|| (i = s, match("7") )
|| (i = s, match("8") )
|| (i = s, match("9") )
|| (i = s, match("0") )
}
const Parser (input){
let i = 0
const match = (term) => term === input[i++];
const Exp = () => {
const s = i;
return (i = s, Term() && match("+") && Exp() )
|| (i = s, Term() )
}
const Term = () => {
const s = i;
return (i = s, match("(") && Exp && match(")") )
|| (i = s, Int() && match("*") && Term() )
|| (i = s, Int() )
}
const Int = () => {
const s = i;
return (i = s, match("1") )
|| (i = s, match("2") )
|| (i = s, match("3") )
|| (i = s, match("4") )
|| (i = s, match("5") )
|| (i = s, match("6") )
|| (i = s, match("7") )
|| (i = s, match("8") )
|| (i = s, match("9") )
|| (i = s, match("0") )
}
return Exp()
}
email-address = local "@" domain
local = local-word *("." local-word)
domain = 1*(sub-domain ".") top-domain
local-word = 1*local-char
sub-domain = 1*sub-domain-char
top-domain = 2*6top-domain-char
local-char = alpha / num / special
sub-domain-char = alpha / num / "-"
top-domain-char = alpha
alpha = %d65-90 / %d97-122
num = %d48-57
special = %d33 / %d35 / %d36-39 / %d42-43 / %d45 / %d47
/ %d61 / %d63 / %d94-96 / %d123-126